
Muhammad Ziaullah Khan
Chief Compliance Officer & Head of ICCD at United Commercial Bank Limited
Data’ comes from a singular Latin word, datum, which originally meant ‘something given’. Its early usage dates back to the 1600s. Over time ‘data’ has become the plural of datum. Data are simply facts or figures, bits of information, but not information itself. When data are processed, interpreted, organized, structured or presented so as to make them meaningful or useful, they are called information. Information provides context for data.
Data management is the development, execution and supervision of plans, policies, programs and practices that store, transmit, control, protect, deliver and enhance the value of data and information assets.
The goal of a data management plan is to consider the many aspects of data management, metadatageneration, data preservation, and analysis before the project begins; this ensures that data are well-managed in the present, and prepared for preservation in the future.
Preparing a data management plan before data are collected ensures that data are in the correct format, organized well, and better annotated. This saves time in the long term because there is no need to re-organize, re-format, or try to remember details about data. One component of a good data management plan is data archiving and preservation. By deciding on an archive ahead of time, the data collector can format data during collection to make its future submission to a database easier. If data are preserved, they are more relevant since they can be re-used.
DATA MANAGEMENT CONCERNS
Scalability: Data based applications in use today can be scaled without major issue by increasing the underlying hardware resources. But for those applications for which it is an issue it is usually a major issue, and the most common category of data based application that has such scalability limitations is internet applications and web based services. The problems with scaling this type of application are firstly, the scalability requirements are hard to predict in advance and secondly they can change instantly based on sudden change in requirements or in policy.
Data Volume: Today in most database applications, much of the data contained is non-active historical data that is there solely for the purpose of future reference should it so be required. Managing the vast volumes of data including log files to ensure the balance between data availability and manageability is maintained moving forward causes a concern issue.
Data Storage: Current technologies of data management systems are not able to satisfy the needs of big data, and the increasing speed of storage capacity is much less than that of data. Big data is heterogeneous. Storing and analyzing large volumes of data that is crucial for a company to work requires a vast and complex hardware infrastructure. If more and complex data is stored, more hardware systems will be needed. Data and transaction logs are stored in multi-tiered storage media. As the size of data set has been, and continuous to be, growing exponentially, scalability and availability have necessitated auto-tiering for data storage management.
Data compression: As computer file size increases day by day and data becomes more complex, more storage space is required for archiving and backing up. Data compression is particularly useful in communications because it enables devices to transmit or store the same amount of data in fewer bits. Data compression may overcome physical size limitations of storage devices. By trying to compress huge volumes of data and then analyze it, is a tedious process which will ultimately prove more ineffective. To compress data it takes time, almost the same amount of time to decompress it in order to analyze it so it can be displayed, by doing this, displaying the results will be highly delayed.
Data transmission: Every year the data transmitted over the internet is growing exponentially. By the end of 2016, Cisco estimates that the annual global data traffic will reach 6.6 zettabytes. There are also strong interests in exploiting big data to gain business profits. Advances in sensor networking, cyber-physical systems, and Internet of things have enabled financial service companies, retailers, and manufacturers to collect their own big data in their business processes. On the other hand, through such utility computing services as cloud computing, high-performance IT infrastructures and platforms that were previously unaffordable are now available to a broader market of medium or even small companies. With the growing capacity of access links, network bottlenecks are observed to be shifting from the network edges in access networks to the core links in the Internet backbone. To improve the throughput of end-to-end data transmission, path diversity should be explored, which utilizes multiple paths concurrently to avoid individual bottlenecks.
Data Processing: For processing large quantities of data that is extremely complex and various there needs to be a set of tools that are able to navigate through it and sort it. Data can be used for predictive analytics, an element that many companies rely on when it comes to see where they are heading. Streaming information in real-time is becoming a challenge that must be overcome by those companies that provides such services, in order to maintain their position on the market. The software architecture tries to compensate the lack of processing speed by sorting and ordering the requests, so that processes can be optimized in order to achieve best performance.
Data Sharing: Every person and company has at their disposal large amount of information that can use it to serve their purposes. Everything is available only if everyone shares it. Regarding persons, there is a difference between what is personal and what can be made public. The issue of what is personal and what is public mostly resides in the point of view of the services that they use. Sharing the information proves to be one of the most valuable characteristics of development. Information about almost anything can be found by simply doing a ‘Search’. A more transparent representation of current information that a company holds will be in the advantage of everyone. By doing this, the type of information and the way it is structured can help further development of software systems that can be standardized and can work with all types of data imported from various sources.
Data Security: Data is routinely replicated and migrated among a large number of nodes. In addition, sensitive information can be stored in system logs, configuration files, disk caches, error logs, and so on. Organizations may leverage data from enterprise resource planning systems, customer relationship management platforms, video files, spreadsheets, social media feeds, and many other sources. Further, more data sources are added all the time. These data sources can include personally identifiable information, payment card data, intellectual property, health records, and much more. Consequently, the data sources being compiled need to be secured in order to address security policies and compliance mandates.
Data Encryption: Manipulating data, collecting it and store it in a proper manner that is in the advantage of the beneficiary and as well for the user that provides the data, will remain an important issue to be solved by IT security specialists. One solution for this matter, besides keeping all the data stored on an ‘in-house’ Data system, is to encrypt it. By encrypting the data with a personal key it makes it unreadable for persons that don’t have the clearance to see it. The downside of using encryption is that you have to use the same software that encrypted it to read it and analyze it, or, in worst case scenario, if you want to make it available for every software that is on the market the process implies more steps which take time. First step is to encrypt it using special encryption software, after that, each time the data is used for manipulation or analysis it must be decrypted and after work is finished, encrypt it again. While some vendors offer big data encryption capabilities, these offerings only secure specific big data nodes, not the original data sources that are fed into the big data environment or the analytics that come out of the environment. Further, these big data encryption offerings don’t even secure all the log files and configuration information associated with the big data environment itself.
Data Recovery: Due to the complexity of doing transaction based recovery, most database applications no longer ‘delete’ any data instead a status flag to indicate that data is in a deleted state. Changes to the data are also logged as change history which is also infrequently actually deleted. This allows for application based recovery of that transaction but significantly contributes to the increasing data volumes being experienced. Methods for ensuring individual pieces of data can be rolled back without keeping it within the highly used data set perpetually is a complex issue.
Data Auditability: This is due to increased focus on security, risk, accountability and avoidance of fraud and corruption. While security prevention measures (logins, firewalls, tokens etc.) are important to prevent unauthorized access to the data in the first place, most breaches occur by users who are authorized but are either negligent or malicious.
Inefficient use of Resources: Database systems are typically implemented in a manner which sees a physical server provide a platform for one or a small number of applications. This approach has had its benefits from an implementation perspective including, the complete costs (hardware, software, license, management) can be easily calculated and assigned to a project/department, the risk of impacting other applications is low, sizing an environment is easier as only a single workload is taking into consideration and so on. However due to the continual increase in applications this has led to large numbers of database servers being implemented. There are commonly dozens of such servers in small organizations, hundreds in medium sized organizations and even thousands of database servers being implemented in large enterprises. One of the several issues with this approach is that it leads to significant inefficiency in resource utilization across the entire infrastructure.
DATA MANAGEMENT KEY ACTIVITIES
Data Policy development: A Good Data Management procedure requires is to define a Data Policy. This policy document to be approved at senior levels in the public body, and the senior executive who owns the policy, manages the resources for its implementation. Data Policy Statement should include the events like: Data acquisition, Data accountability & authenticity, Data use & exchange etc.
Data Ownership: A good Data Management is the clear identification of the owner of the data. Normally this is the organization or group of organizations that originally commissioned the data acquisition or compilation and retains managerial and financial control of the data. The Data Owner has legal rights over the dataset, Intellectual Property Rights (IPR) and the Copyright. Data ownership implies the right to exploit the data, and if continued maintenance becomes unnecessary or uneconomical, the right to destroy them, subject to the provisions of the Public Records and Freedom of Information acts. Ownership can relate to a data item, a dataset or a value-added dataset.
Metadata Compilation: A good metadata record enables the user of a dataset or other information resource to understand the content of what they are reviewing, its potential value and its limitations.
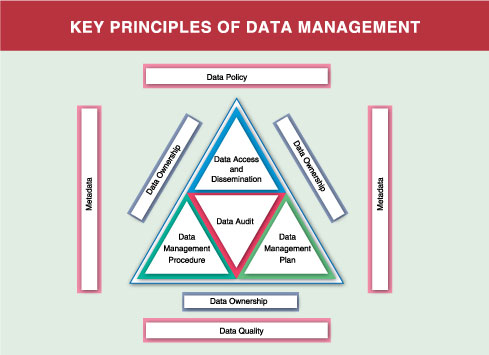
Data Lifecycle Control: Good Data Management requires that the whole life cycle of datasets to be managed carefully. This includes:
» Business justification, to ensure that thought has been given to why new data are required rather than existing data amended or used in new ways, how data can be specified for maximum use including the potential to meet other possible requirements, and why the costs of handling, storing and maintaining these data are acceptable and recoverable.
»Data specification and modeling, processing, database maintenance and security, to ensure that data will be fit for purpose and held securely in their own databases.
»Ongoing data audit, to monitor the use and continued effectiveness of the data.
»Archiving and final destruction, to ensure that data are archived and maintained effectively until they are no longer needed or are uneconomical to retain.
Data Quality: A Good Data Management also ensures that datasets are capable of meeting current needs successfully and are suitable for further exploitation. The ability to integrate data with other datasets is likely to add value, encourage ongoing use of the data and recover the costs of collecting the data. The creation, maintenance and development of quality data require a clear and well-specified management regime.
Data Access and Dissemination: This aspect depends upon the business and the financial policy of the organization.
INTEGRATED DATA MANAGEMENT
Integrated data management (IDM) is a tools approach to facilitate data management and improve performance. IDM consists of an integrated, modular environment to manage enterprise application data, and optimize data-driven applications over its lifetime.
IDM’s purpose is to:
» Produce enterprise-ready applications faster
» Improve data access, speed iterative testing
» Empower collaboration between architects, developers and DBAs
» Consistently achieve service level targets
» Automate and simplify operations
» Provide contextual intelligence across the solutionpack
» Support business growth
» Accommodate new initiatives without expanding infrastructure
»Simplify application upgrades, consolidation and retirement
» Facilitate alignment, consistency and governance
» Define business policies and standards up front; share, extend, and apply throughout the lifecycle
DATABASE MANAGEMENT
A database is an organized collection of data. It is the collection of schemas, tables, queries, reports, views, and other objects. The data are typically organized to model aspects of reality in a way that supports processes requiring information, such as modeling the availability of rooms in hotels in a way that supports finding a hotel with vacancies.
A database management system (DBMS) is a computer software application that interacts with the user, other applications, and the database itself to capture and analyze data. A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases. Well-known DBMSs include MySQL, PostgreSQL, MongoDB, MariaDB, Microsoft SQL Server,Oracle, Sybase, SAP HANA, MemSQLandIBMDB2.
A database is not generally portable across different DBMSs, but different DBMS can interoperate by using standards such as SQL and ODBC or JDBC to allow a single application to work with more than one DBMS. Database management systems are often classified according to the database model that they support; the most popular database systems since the 1980s have all supported the relational model as represented by the SQL language. Sometimes a DBMS is loosely referred to as a ‘database’.
Database servers are dedicated computers that hold the actual databases and run only the DBMS and related software. Database servers are usually multiprocessor computers, with generous memory and RAID disk arrays used for stable storage. RAID is used for recovery of data if any of the disks fail. Hardware database accelerators, connected to one or more servers via a high-speed channel, are also used in large volume transaction processing environments. DBMSs are found at the heart of most database applications. DBMSs may be built around a custom multitasking kernel with built-in networking support, but modern DBMSs typically rely on a standard operating system to provide these functions from databases before the inception of Structured Query Language (SQL). The data recovered was disparate, redundant and disorderly, since there was no proper method to fetch it and arrange it in a concrete structure.
DATABASE ADMINISTRATION
The role of Database Administrator may include capacity planning, installation, configuration, database design, migration, performance monitoring, security, troubleshooting, as well as backup and data recovery.
» Installing and upgrading the database server and application tools
» Allocating system storage and planning future storage requirements for the database system
» Modifying the database structure, as necessary, from information given by application developers
» Enrolling users and maintaining system security
» Ensuring compliance with database vendor license agreement
» Controlling and monitoring user access to the database
» Monitoring and optimizing the performance of the database
» Planning for backup and recovery of database information
» Maintaining archived data
» Backing up and restoring databases
» Contacting database vendor for technical support
» Generating various reports by querying from database as per need
DATA MINING
Data mining is the computational process of discovering patterns in large data sets involving methods at the intersection of artificial intelligence,machine learning,statistics, anddatabase systems.The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Data mining is the analysis step of the “knowledge discovery in databases” process, or KDD. Data mining is the process of applying various methods with the intention of uncovering hidden patterns in large data sets. It bridges the gap from applied statistics and artificial intelligence (which usually provide the mathematical background) to database management by exploiting the way data is stored and indexed in databases to execute the actual learning and discovery algorithms more efficiently, allowing such methods to be applied to ever larger data sets.
DATA WAREHOUSE (DW)
DWs are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place and are used for creating analytical reports for knowledge workers throughout the enterprise. The data stored in the warehouse is uploaded from the operational systems (such as marketing or sales). The data may pass through an operational data store and may require data cleansing for additional operations to ensure data quality before it is used in the DW for reporting.
BENEFITS OF USAGE OF DATA WAREHOUSE
A data warehouse maintains a copy of information from the source transaction systems. This architectural complexity provides the opportunity to:
» Integrate data from multiple sources into a single database and data model. Mere congregation of data to single database so a single query engine can be used to present data is an ODS.
» Mitigate the problem of database isolation level lock contention in transaction processing systems caused by attempts to run large, long running, analysis queries in transaction processing databases.
» Maintain data history, even if the source transaction systems do not.
» Integrate data from multiple source systems, enabling a central view across the enterprise. This benefit is always valuable, but particularly so when the organization has grown by merger.
» Improve data quality, by providing consistent codes and descriptions, flagging or even fixing bad data.
» Present the organization’s information consistently.
» Provide a single common data model for all data of interest regardless of the data’s source.
» Restructure the data so that it makes sense to the business users.
» Restructure the data so that it delivers excellent query performance, even for complex analytic queries, without impacting the operational systems.
» Add value to operational business applications, notably customer relationship management (CRM) systems.
» Make decision–support queries easier to write. Optimized data warehouse architectures allow data scientists to organize and disambiguate repetitive data.
DATA GOVERNANCE
Data governance is a quality control discipline for assessing, managing, using, improving, monitoring, maintaining, and protecting organizational information. It is a system of decision rights and accountabilities for information-related processes, executed according to agreed-upon models which describe who can take what actions with what information, and when, under what circumstances, using what methods.
OBJECTIVES / GOALS OF DATA GOVERNANCE
Data governance encompasses the people, processes, and information technology required to create a consistent and proper handling of an organization’s data across the business enterprise. Goals may be defined at all levels of the enterprise and doing so may aid in acceptance of processes by those who will use them. Some objectives / goals of data governance include:
» Increasing consistency and confidence in decision making
» Decreasing the risk of regulatory fines
» Improving data security
» Defining and verifying the requirements for data distribution policies
» Maximizing the income generation potential of data
» Designating accountability for information quality
» Enable better planning by supervisory staff
» Minimizing or eliminating re-work
» Optimize staff effectiveness
» Establish process performance baselines
DATA MANAGEMENT AUDIT
Data Management audits are recommended to ensure that the management environment for given datasets are being maintained. Their purpose is to provide assurance to the Data Management organization that the resources expended are being used appropriately. Audits of major datasets should be commissioned to ascertain the level of compliance with data policies and the Data Management plans and procedures that have been prepared.







{kind=link}